注意点
- cin cout 换成 scanf printf
- 用空间换速度:三层循环写成两层。https://www.acwing.com/problem/content/1223/
- scanf 读字符容易包括空格回车,所以建议直接读字符串
- 超过10 0000用scanf
- 遇到sf用exit(0)二分查找错误
- 整数类型大于4位用long long
- while(x)只是判断不等于0
- strlen(sc[i]+1)若字符串从第一个位置开始
#define x first #define y second typedef pair<int,int> PII PII a[100]; a[1] = {1,2} makepair1
2
3
4
5
6
7
8
9
10-

## 函数
### < algorithm >中的函数
```cpp
sort(a+1,a+n+1); 起始位置到终点位置。常与pair进行联合使用,先排pair的first再排pair的second
< sstream >
- getline()
1 | string line; |
<string.h>
1 | void *memset(void *str, int c, size_t n) |
< queue >
1 | 升序队列,小根堆 |
< map >
1 | map<typename1,typename2>mp; |
可用于字符串统计
1 | unordered_map<elemType_1, elemType_2> |
输入
1 | while(scanf("%d%d%d",&n,&m,&k) != -1) |
所有区间的i
1 | for(int i = 1; i <= n; i++) |
所有区间段
按区间大小从小到大枚举
1 | for(int len = 2; len <= n; len++) |
取整
上取整
- int(ce /ceil 返回double 类型 < cmath>
- a mod b = (a + b - 1) / b = (a - 1) / b + 1
排序
快速排序
https://www.zhihu.com/search?type=content&q=%20%E5%BF%AB%E9%80%9F%E6%8E%92%E5%BA%8F
这个和Y总的代码实现不同,但思维是相通的
- 当边界用i,边界点不能取q[l],例[0,1]会出现死循环
- 当边界用j,边界点不能取q[r],例[0,1]会出现死循环
1 | void quick_sort(int q[], int l, int r) |
归并排序
- 对比
双指针
为了维护操作某一段区间
找单调性
设置i,j双指针,j经过每个循环+1,当不满足条件时,i++,直至满足条件。
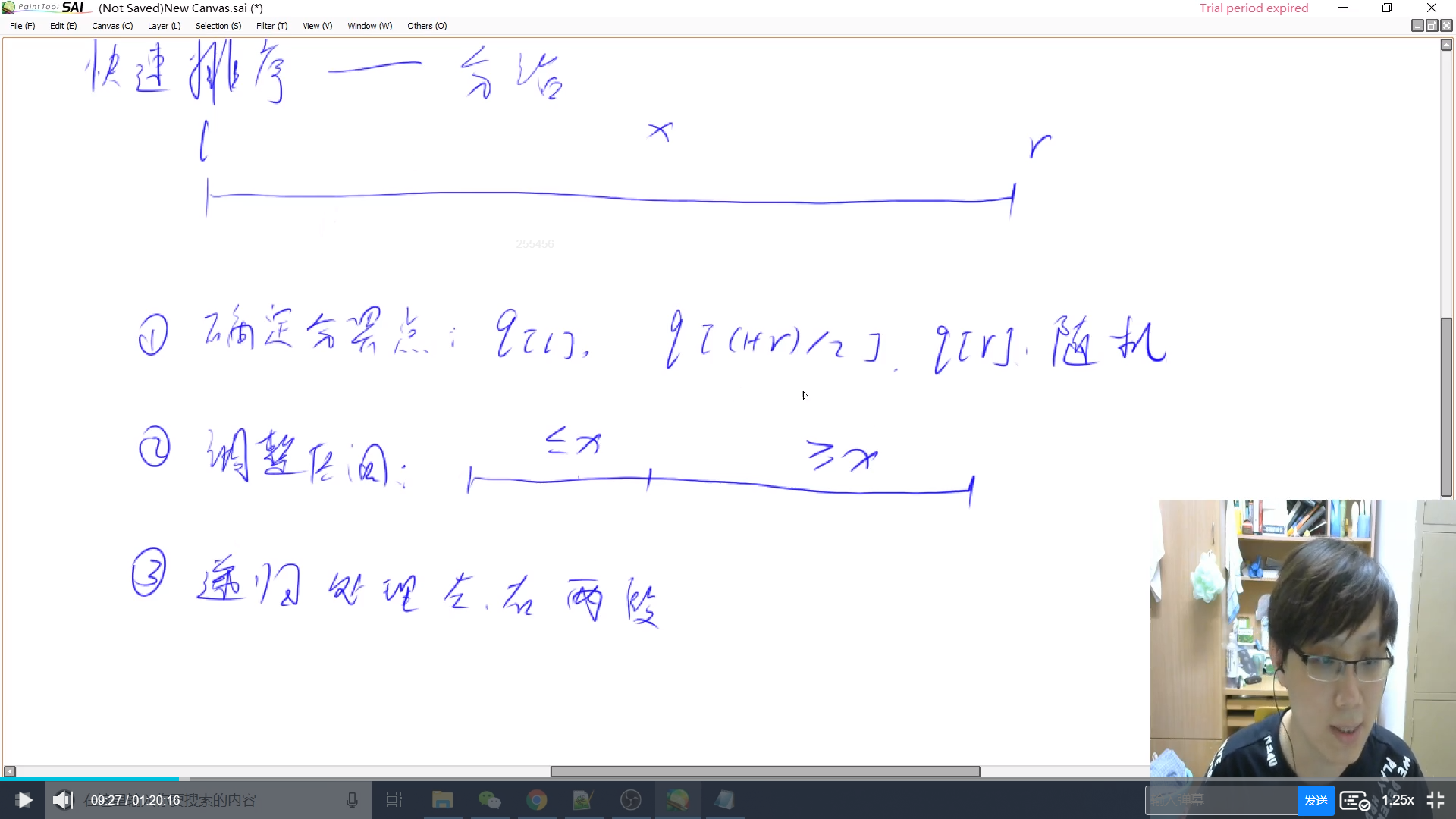
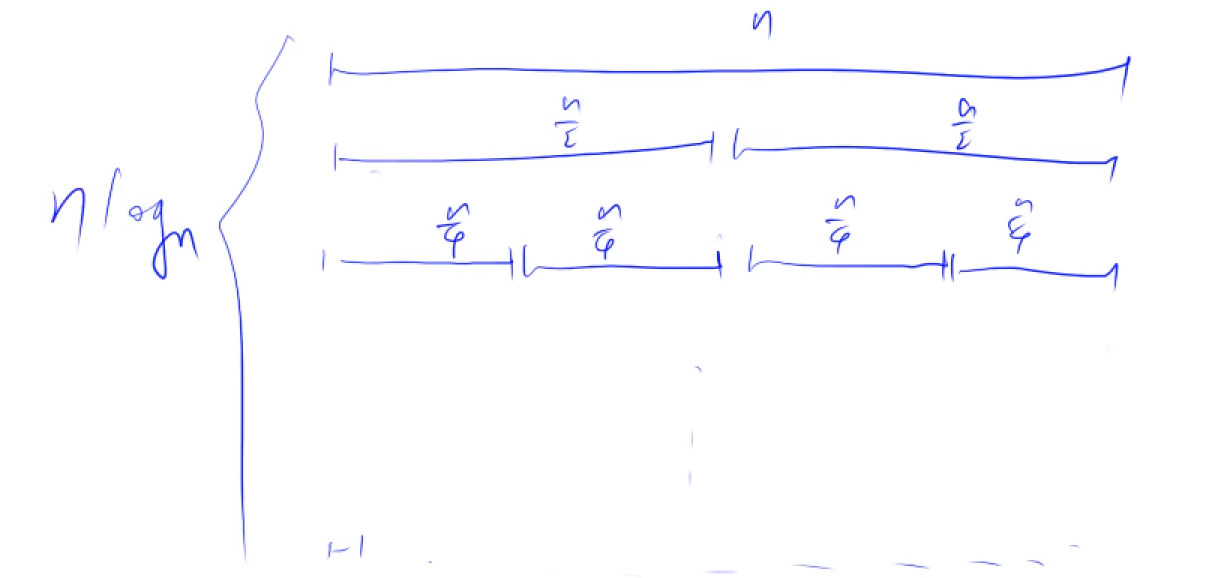
树状数组和线段数
快速求前缀和(区间查询) O(logn)
在某个位置上的数加上一个数(单点修改)O(logn)
- 线段数 完全包含 树状数组
- 能用树状数组就用树状数组
- 从1开始
树状数组
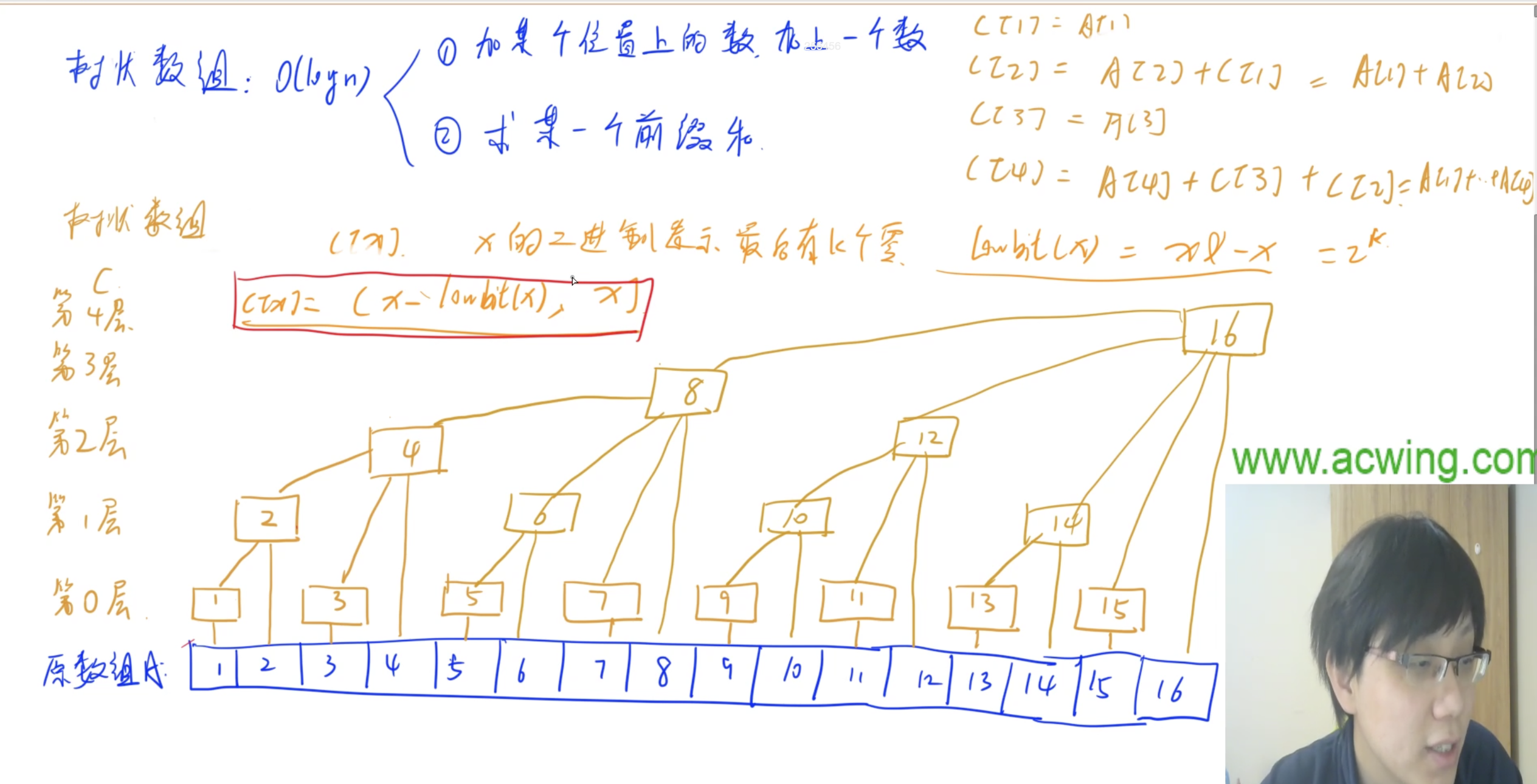
- tr[x] 表示区间和是**(x-lowbit(x),x]**, 记住就行
- add(x, k)让后面所有包含元素x区间和都增加k
- query(x) 累加x前面全部的元素,每个i包含了(i-lowbit(i),i]的数
1 | //返回二进制的第一个非零的1 |
线段数

1 | struct node{ |
二分和前缀和
整数二分
- mid = (l + r + 1) / 2 ,若 mid = (l + r) / 2 有边界问题:若 l = r - 1,mid = l,边界还是 l 和 r 出现死循环。
- mid = (l + r + 1) / 2 取上界,mid = (l + r) / 2 取下界。

实数二分
- 不用考虑边界
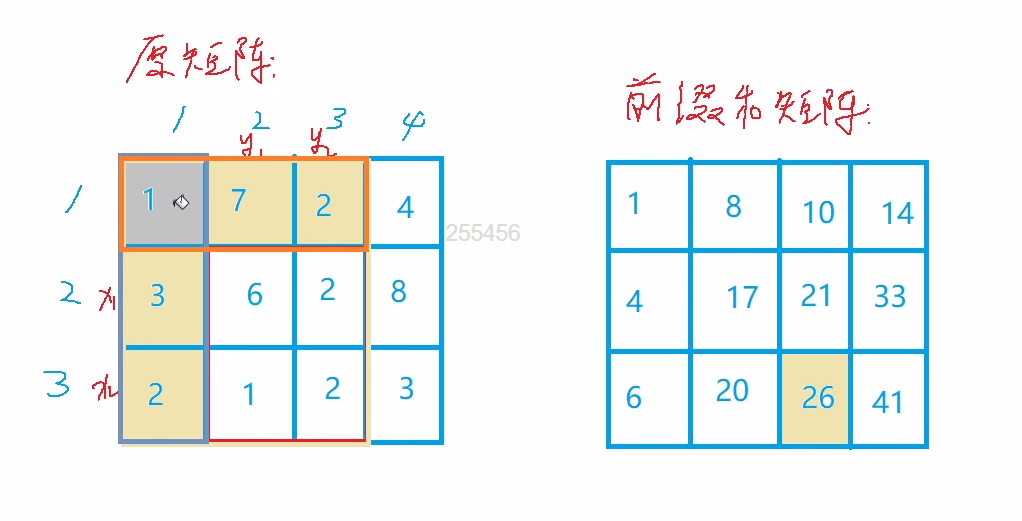
前缀和
- 预处理:用数组纪录和
https://www.acwing.com/problem/content/797/ - 若空间不够,原数组可省略,只用前缀和数组

一维差分
快速给某一个区间加上一个数,最终求每一个数的值。
核心操作:b[l] += x, b[r+1] -= x
首先给定一个原数组a:a[1], a[2], a[3],,,,,, a[n];
然后我们构造一个数组b : b[1] ,b[2] , b[3],,,,,, b[i];
使得 a[i] = b[1] + b[2 ]+ b[3] +,,,,,, + b[i]
也就是说,a数组是b数组的前缀和数组,反过来我们把b数组叫做a数组的差分数组。
二维差分

KMP
1 | // s[]是长文本,p[]是模式串,n是s的长度,m是p的长度 |
Trie
高效存储和查找字符串集合的数据结构
题目限制一般在26个字母
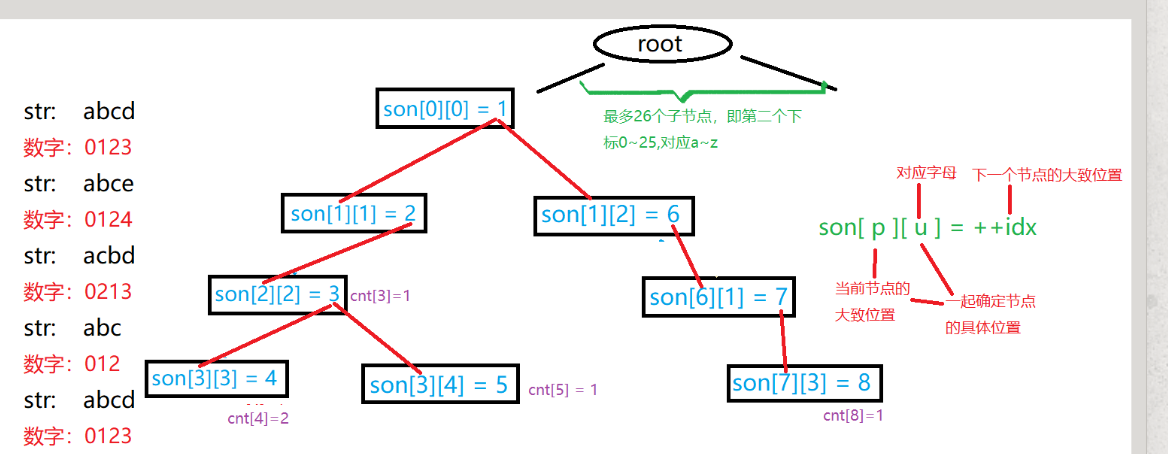
插入
1 | void insert(char *str) |
查找
1 | int query(char *str) |
并查集
将两个集合合并hi
询问两个元素是否在一个集合当中
原理:每个集合用一棵树来表示。树根的编号就是整个集合的编号。每个节点存储它的父节点,p[x]表示x的父节点。

变形:找到需要维护的变量
1 | int find(int x) |
堆

- 完全二叉树:除了最后一层节点,上面所有节点都是满的,最后节点从左到右排列。
- 小根堆:每个点小于等与左右儿子,所以根节点是最小值。
- 存储;down(X); up(x);
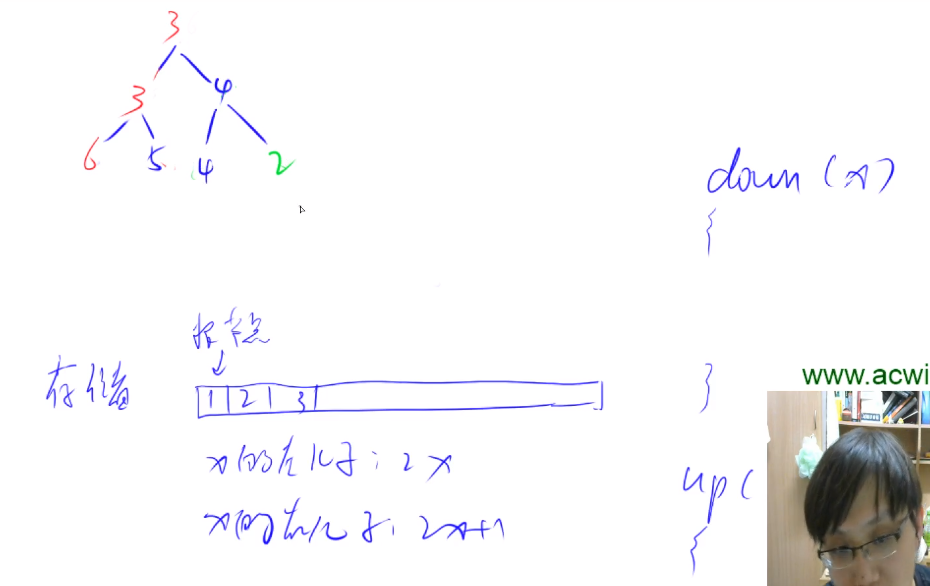
为什么从2/n开始down?
因为n是最大值,n/2是n的父节点,因为n是最大,所以n/2是最大的有子节点的父节点,所以从n/2往前遍历,就可以把整个数组遍历一遍
理解heap_swap中的次序
房间a中放有元素10,房间b中放油元素20。
10(犯人1)是第一个插入的,20(犯人二)是第二个插入的。
h[a] = 10, h[b] = 20 swap: h[a] = 20,h [b] = 10
hp[a] = 1 ,hp[b] = 2 swap:hp[a] = 2 ,hp[b] = 1
ph[1] = a ,ph[2] = b swap:ph[1] = b ,ph[2] = a
1 | void heap_swap(int a, int b) |
数学问题
- 尽力分析
- 打表找规律 用dfs
- a, b的最大不能组成的数:(a - 1) * (b - 1) - 1
动态规划
dp分析法:
状态表示
集合:不重不漏
属性:最大值,最小值,数量
状态计算:用集合表示,不重不漏
背包问题——最值、个数
- 没有固定模板,核心在于状态表示和转移。
- 0-1背包:物品只能选一次。一维二层枚举需逆序,因为f[ j ]需由f[ i-1 ][ j ]状态更新而来。
1 | f[i][j] = max(f[i-1][j], f[i-1][j-v) + w) // 二维 |
- 完全背包:物品可以用无数次。

1 | f[i][j] = max(f[i-1][j], f[i][j-v) + w) // 二维 |
- 多重背包:物品可以一次或多次。
法一:将多重背包拆解成01背包
法二:当数据量大,需通过二进制优化。
二进制优化:最少用几个数能表示小于等于k的所有数。可以将一个数拆成几个数,把一个问题拆成logn。
分组背包:每一组选一个,最后可看成0-1背包问题

背包问题参考 https://blog.csdn.net/raelum/article/details/128996521
数位统计——==分情况讨论==
递归和递推
- 递归将问题分为子问题
- 递推由子问题推
枚举
- 判断闰年:
1 | int leap = year % 100 && year % 4 == 0 || year % 400 == 0; |
距离公式
- 曼哈顿距离
$d_{M}(P_1, P_2) = |x_1 - x_2| + |y_1 - y_2|$
欧几里得距离
$$ d(x_1,x_2) = \sqrt{\sum_{i=1}^n{(x_{1,i}-x_{2,i})^2}} $$
单调队列
- 求窗口里面的最大最小值
- 求离他最近比他小的元素或最大的元素
狄杰斯塔拉
不断选择距离最近的点
快速幂
快速求a * (b^x)
1 | while(x) |
矩阵乘法
1 | void mul(int res[][N], int a[][N], b[][N]) |